













[ad_1]
Our world is a nuanced and complex place, best experienced through the mixed modalities of our senses. Given this, AI researchers have also started applying multimodal strategies to create in-context vision and language models, hoping to improve how these AI systems see and interpret our world.
Earlier this month Seattle-based Allen Institute for AI (AI2) released an open multimodal augmentation of the popular text-only corpus, c4. This new data set, which AI2’s researchers dubbed Multimodal C4, or mmc4, is a publicly available model that interleaves text and images in a billion-scale data set. This open data set will allow researchers to explore new ways to improve AI’s ability to interpret and learn, so they can provide us with better tools in the future.
“These multimodal models can operate not only on language, but also images and audio,” said Jack Hessel, one of the researchers working on the project. “Multimodal C4 has been really exciting for me.”
The c4 and mmc4 corpuses are both derived from data collected by Common Crawl, a nonprofit organization that crawls the web, then provides its archives and datasets to the public for free. Common Crawl generates around a petabyte of data and is hosted on AWS. Google used Common Crawl in 2019 to develop the Colossal Clean Crawled Corpus, or c4, which was aggregated by Google to train its Text-to-Text Transfer Transformer or T5 model.
The AI2 team augmented c4 by interleaving it with images gathered from the crawl, resulting in its new mmc4 dataset. This billion-scale corpus of images augments the associated text to yield a rich, open data set that can then be freely used by researchers and developers to develop improved AI models.
In its initial application, mmc4 was used to provide training data for OpenFlamingo, the first public model trained on this corpus. It’s a framework that enables training and evaluation of large multimodal models (LMMs), in order to carry out a diverse range of vision-language tasks.
An open-source reproduction of DeepMind’s Flamingo model, OpenFlamingo was developed to make its capabilities more widely available. Since Flamingo’s training data isn’t available to the public, this open version attempts to implement the same architecture. To do this, it leverages features like perceiver resamplers and gated cross-attention layers to incorporate multiple images and video frames with their associated text.
This kind of in-context vision and language model supports interleaved sequences of images and text as its input. Importantly, it enables few-shot learning — the ability to infer and learn from a small number of examples. It also provides more complex prompts that involve interactions between images. For instance, it can be queried about which features two different images have in common.
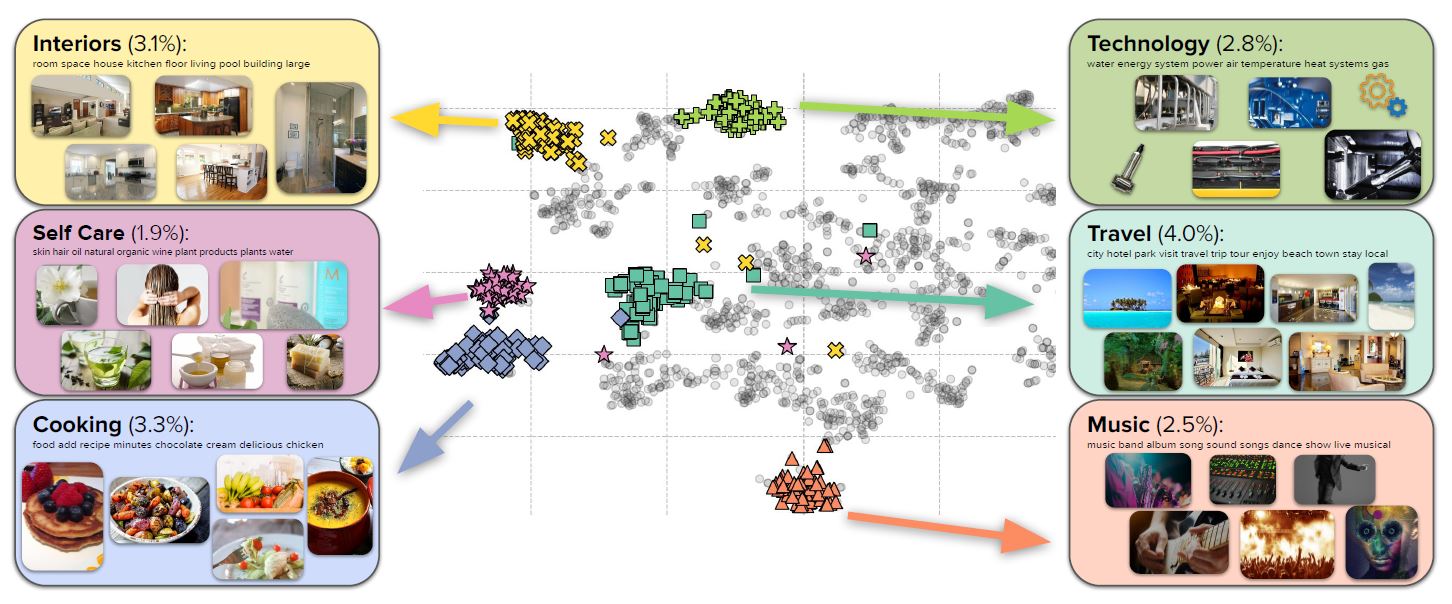
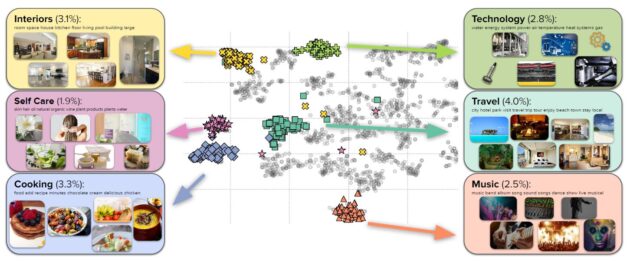
By using a linear assignment algorithm to interleave images into longer bodies of text, the model can perform many different tasks. This includes answering questions and performing tasks that cover everyday topics like cooking, travel, technology, etc. Random samples indicate that a vast majority of images (90%) are topically relevant and that the linear assignment process frequently selected individual sentences that were well-aligned with each image (78%). After filtering out NSFW images, ads, etc., the corpus contains 103 million documents containing 585 million images interleaved with 43 billion English tokens.

To achieve all of this, the research team began by retrieving the original webpages from Common Crawl, then collected the downloadable images that had previously been excluded from c4. Data cleaning was carried out through deduplication and content filtering, which aimed to eliminate non-safe for work (NSFW) and unrelated images, such as advertisements. Additionally, the researchers ran face detection and discarded images with positive identifications. Finally, images and sentences were interleaved using a technique known as bipartite matching, an algorithm based on graph theory that helps determine where in the text an image should be placed.
Perhaps not surprisingly, multimodal systems like mmc4 and OpenFlamingo have several possible applications that are different from other, more fundamental text-only language frameworks and models. Because large language models like mmc4 can answer questions about visual content, there are many potential use cases for education and training, healthcare, and intelligence work, as well as improving accessibility and usability in UX design. This includes generating more accurate alt-text for web images. These text-only interpretations of images provide ways for differently-abled users to access images on the web.
“I think one important use case is image accessibility,” Hessel noted. “There’s a lot of great work from human computer interaction that suggests that automated tools can provide a good starting point for improving alt-text for lead images. So, I think there’s a really important use case for accessibility purposes.”
In addition to the full version of the corpus, two additional subsets have been constructed to make mmc4 more usable, secure and environmentally friendly. Currently, this includes a fewer-faces subset that aims to remove images containing detected faces and a core subset that uses more stringent filtration criteria to scale back the original corpus by an order of magnitude. This reduces resource requirements, improves performance, and requires less compute, or processing cycles, so less energy is needed to run them.
Multimodal C4 is a part of AI2’s Mosaic group, which investigates and develops the commonsense capabilities of machines. While much of this work is text-based, mmc4 offers a different approach to this work. According to Hessel, “Mosaic is focused on common sense reasoning with most of the folks in our group working with text only models, so focusing on multimodal models is a bit of an anomaly.”
“Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved With Text” is the work of Wanrong Zhu, Jack Hessel, Anas Awadalla, Samir Yitzhak Gadre, Jesse Dodge, Alex Fang, Youngjae Yu, Ludwig Schmidt, William Yang Wang, and Yejin Choi.
OpenFlamingo was developed by Meta AI and LAION, a non-profit organization aiming to make large-scale machine learning models, datasets, and related code available to the general public.
Work on Multimodal C4 was supported in part by DARPA MCS program through NIWC Pacific, the NSF AI Institute for Foundations of Machine Learning, Open Philanthropy, Google, and the Allen Institute for AI.
[ad_2]
Source link

{kind=link}